Corpus analysis
a world of possibilities; data and methods
Datasets
- SubIMDB is an amazing source of data from subtitles. Some 38k movies and series subtitles.
- OpenSubtitles2018 might also be good, but I didn't try it
- A huge community-curated list
- Common Crawl Corpus: web crawl data composed of over 5 billion web pages (541 TB)
- Google Web 5gram: contains English word n-grams and their observed frequency counts (24 GB)
- Jeopardy: archive of 216,930 past Jeopardy questions (53 MB)
- Reddit Comments: every publicly available reddit comment as of july 2015. 1.7 billion comments (250 GB)
- SMS Spam Collection: 5,574 English, real and non-enconded SMS messages, tagged according being legitimate (ham) or spam. (200 KB)
- Wikipedia Extraction (WEX): a processed dump of english language wikipedia (66 GB)
- Youtube: 1.7 million youtube videos descriptions (torrent)
- Song lyrics!
- musiXmatch gives word-counts for the top 500 words across all of 237,662 songs
- This is from a website, which seems to have, like, all the songs...
- Billboard 1965 - 2015
- musiXmatch gives word-counts for the top 500 words across all of 237,662 songs
Software
Voyant Tools is the best!
CorText
This online tool is simple, convenient, and powerful. From "word nets" to word2vec encodings, it goes pretty far considering it's a free service. I described this in some detail on Twitter, and highly recommend.
AntConc
To test this tool, I've combined all the NYT obituaries into text files by year, sorted by their publication date. The tool can run most things in a reasonable amount of time on one year segments. It seems if I want to do a multi-year analysis I need to cut down on the number of obituaries in each text file, for example only outputting every 10th obituary or filtering by a key word or concept.
| Description | Screenshot |
|---|---|
| We can usefully look for common multi-word phrases, and use them for further analysis. The software keeps track of frequency, but also some measure of "importance" |
 |
| Searching for a sequence of words will return a list sorted by the next few words. Quite useful. Allows for a very high-level reading of the text, similar to the word tree, inside CorText. |
 |
| We can also do a more formal analysis of the context of a phrase. We can specify a range to the right or left, and the software presents some "stat". |
 |
CoQuery
Here are just a few of the great purported features of this software:
- Use the corpus manager to install one of the supported corpora
- Build your own corpus from PDF, MS Word, OpenDocument, HTML, or plain text files
- Filter your query for example by year, genre, or speaker gender
- Choose which corpus features will be included in your query results
- View every token that matches your query within its context
I'll document what happens when I drop in a large subtitles file, about 500MB, including ~36k movies. It's from SubIMDB.
- It's been running for about a minute, and Coquery is taking 22% of my CPU (a single core, presumably) and about 1GB of my RAM. Because I only uploaded a single file, the status bar is no help in telling me how far it's gone.
- Because there seems to be no end in sight for this upload, I downloaded the files packaged individually by movie. That way the progress bar will work, and I can upload subcorpuses to see how the application works before I invest too much time and effort.
- I got a bit impatient and tried importing the BROWN dataset. It's only 500 documents, easy for something like this to manage. But the import is ~10 per second on this computer. That's pretty slow! (They are just news articles!)
- Here's an example of something I was able to finally accomplish with BROWN:
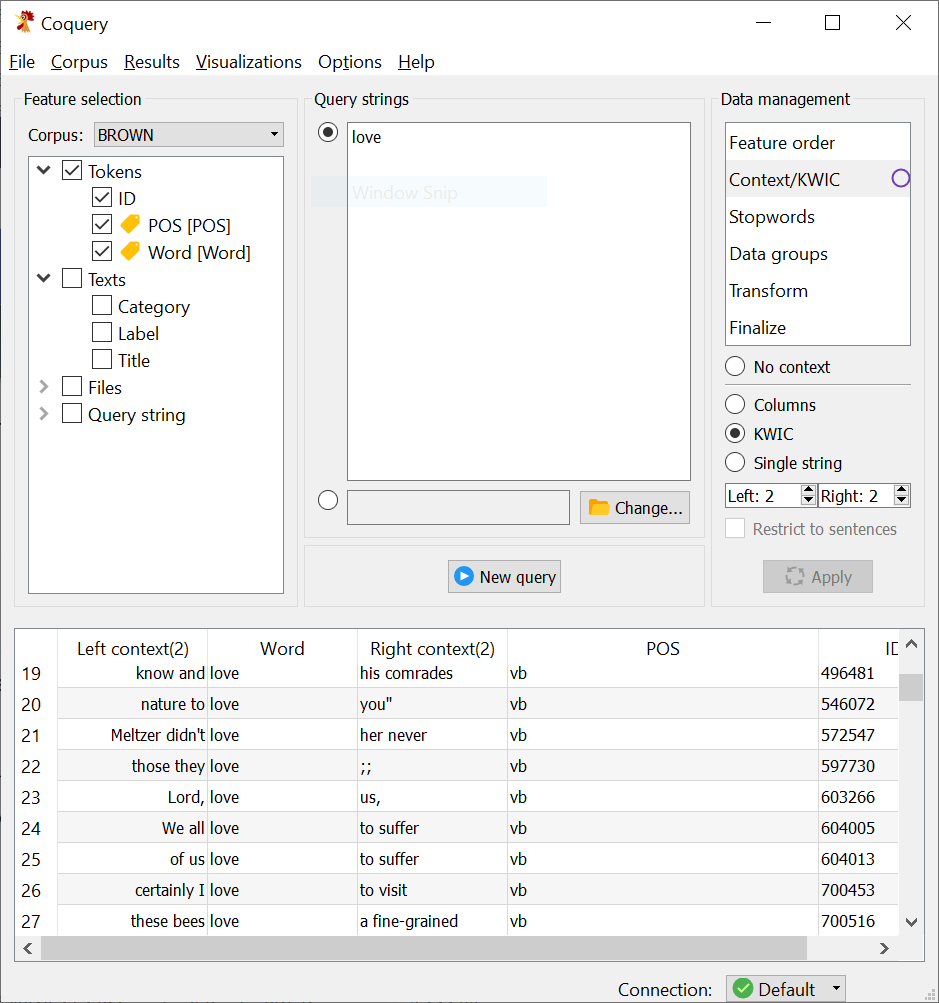
Some other tidbits:
- This software seems really great. It's extensible, thus there are a ton of sensible extensions. For instance (!!!) one which processes sound files, and lets you search them.
- Also, linux installation is sooo easy:
pip install coquery. Although I haven't gotten my (Windows) installation working correctly (lots of bugs), the screenshots on the website look amazing. It seems to be just the tool I need (although it's admittedly inconvenient if it sucks on Windows).
Others I haven't tried
- The IMS Open Corpus Workbench (CWB)
- Seems like it would be great, if it were supported. Looks like it hasn't been touched since 2013.
- and a longer list